Fixed Wing Platform – System ID & Reinforcement Learning
This project involved system identification and reinforcement learning for control of autonomous fixed wing vehicles.
Adversarial & Navigation Informed Guidance with RL
These are two examples of reinforcement learning applications for drones. On the left black agents try to reach a target in green while red agents try to intercept. On the right, agents learn to take a path that minimizes localization uncertainty.
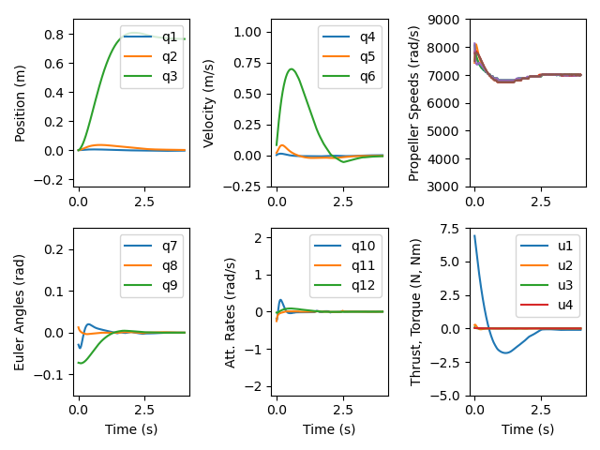
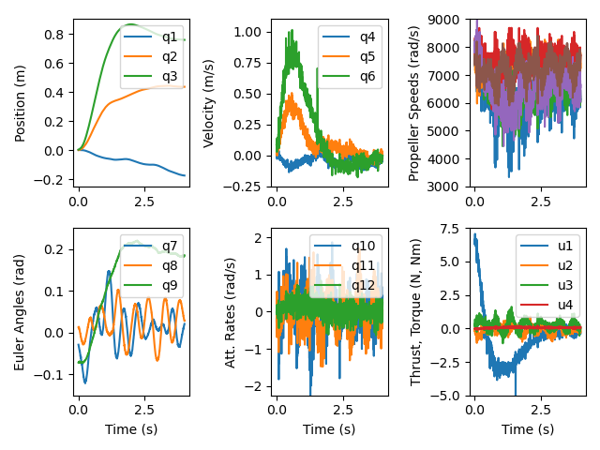
Simulation vs Reality
This project studied the sim2real gap in reinforcement learning. The plots on the left show simulated drone flight paths. The plots on the right show the same flight paths flown in the physical world, notice they’re messier.
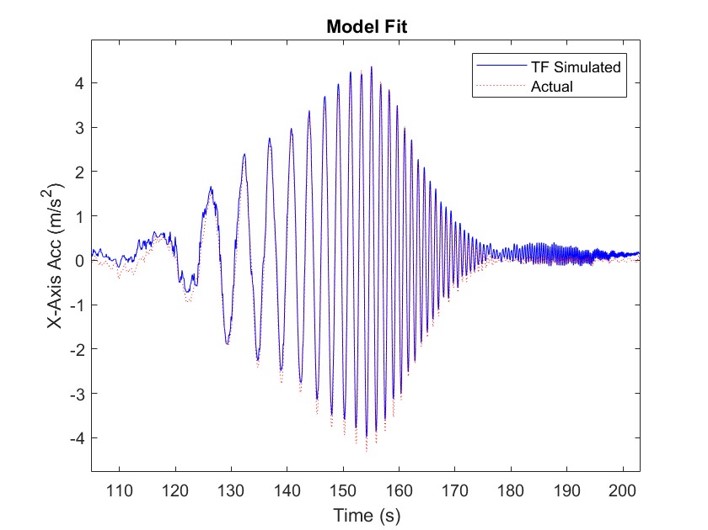
Linear System Identification
One approach to overcoming the sim2real gap is linear system identification, where flight data is used to fit a simplified model of drone dynamics.
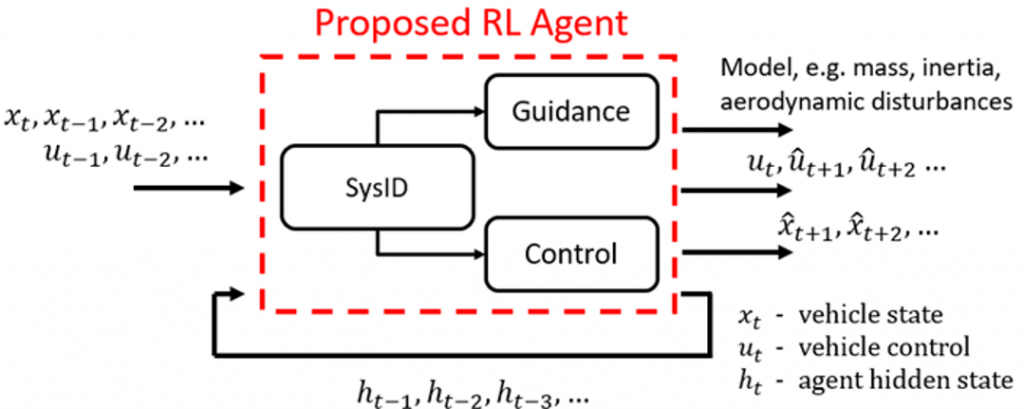
Nonlinear CARRL: Control with Adaptive Robust RL
A more experimental yet potentially more performant system is CARRL: Control with Adaptive Robust Reinforcement Learning. The recurrent architecture is shown on the left, and simulated adaptive flights are shown on the right. Every time color changes, so do aerodynamic and mass properties, yet the RL system is able to adapt and stabilize. This system has been shown to outperform robust PID, MRAC, sliding mode control and trajectory optimization in simulation.